CloudMOA
다양한 클라우드 환경에
대한 통합 관제 솔루션
CloudMOA는 다양한 멀티 / 하이브리드 클라우드 환경의 대규모 IT 인프라와 PaaS 및 MSA 서비스를 통합적으로 관제할 수 있는 솔루션입니다. 인공지능을 활용한 이상 탐지 및 다차원 서비스 레벨의 성능 모니터링 기능이 더해져, 기업의 IT 운영 효율성을 극대화합니다.
특장점
CloudMOA는 설치 편의성과 확장성을 고려한 클라우드 네이티브 아키텍처로 설계되었으며, 대규모 클라우드의 성능 관리에 꼭 필요한 기능을 제공합니다.
-
- 멀티 / 하이브리드 클라우드 지원
- AWS, Azure, GCP, OCI, NCP, KT, NHN
-
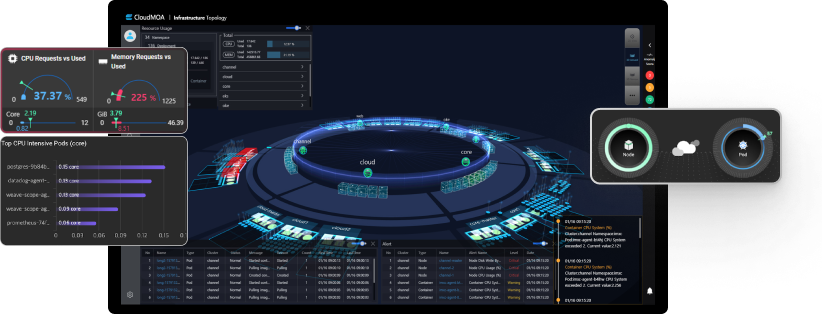
- 2D / 3D 토폴로지 뷰
- 대규모 멀티 클러스터 모니터링
-
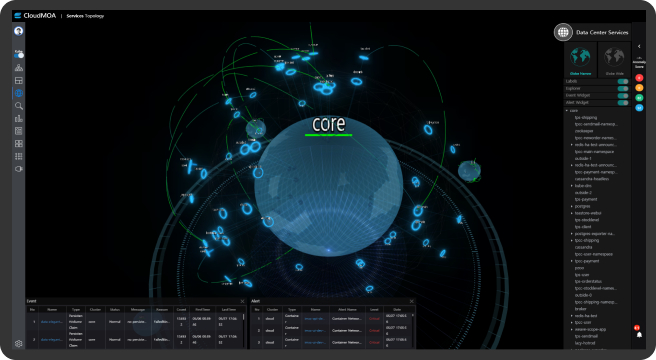
- MSA 환경의 서비스 모니터링
- 복잡한 서비스 간 호출 관계와
트랜잭션 상세 흐름 추적 및 분석
-
- AI 기반 이상 탐지
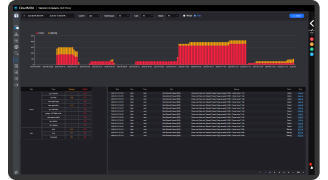
- 과거 데이터를 학습하여 실시간 이상치 탐지
-
- AI 기반 희소 로그 분석
- 머신러닝 기반 로그 분석 및 희소 로그 탐지
-
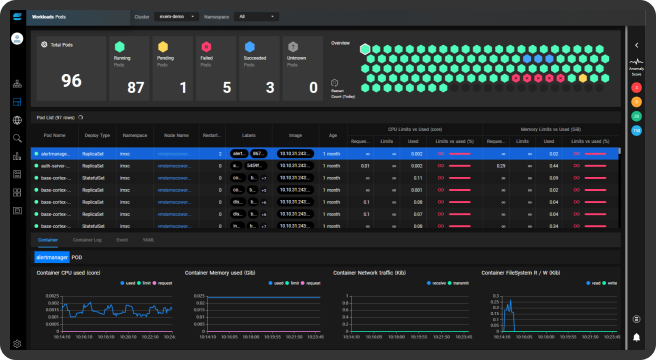
- 서비스 Layer 가시성 확보
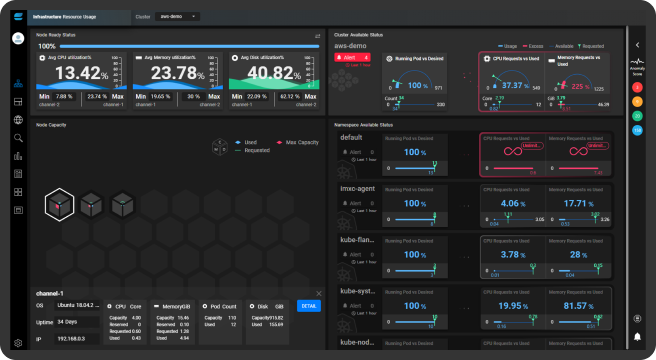
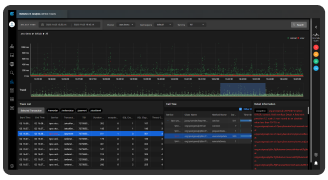
- 실시간 리소스 사용 현황
모니터링 및 알람
-
- 직관적인 UI / UX
- 장애 발생 컨테이너에 대한 빠른
인지를 위한 성능 대시보드 제공
-
- 컨테이너 기반 Agent 설치
- 자동 설치 방식으로 전사
시스템 관리의 편의성 제공
모니터링 뷰
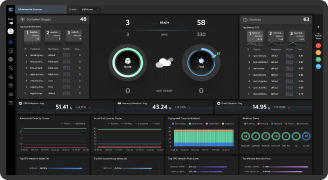
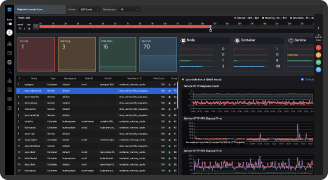
분석 뷰
아키텍처

도입사례
-
은행
프라이빗 PaaS 기반
Kubernetes 통합 운영 시스템 모니터링 구축도입 배경
최초 클라우드 시스템 구축에 따른 IaaS+PaaS+MSA 통합 모니터링의 필요성
도입 효과
• 프라이빗 PaaS 기반 Openshift 운영 시스템 모니터링 및 장애 감지 구현
• IaaS, PaaS 영역을 포함하는 Health Check 기능 연계를 통한 통합 장애 알람 구성
• Container Lifecycle 기능을 통한 Pod 생애 로그 분석 및 원인 분석 가능
• Auto Scale 환경에 대한 신속한 변화 감지와 인사이트로 Infra 운영 효율성 확보
-
카드
멀티 퍼블릭 클라우드
통합 운영 시스템 모니터링 구축도입 배경
다양한 퍼블릭 클라우드 환경에 대한 통합 관제 필요성
도입 효과
• 분산 클라우드 환경에서 고객 서비스의 성능 및 장애에 대한 통합 대시보드를 제공하여 통합 모니터링 관제 시스템 구성
• 멀티 및 하이브리드 클러스터에 대한 통합 모니터링으로 운영 편의성 확보
• MSA 기반 애플리케이션의 실시간 Active Transaction 모니터링으로 실시간 성능 분석 및 개선
• 클라우드 인프라의 효율적인 운영과 관제로 IT 운영 비용 절감 효과
-
프라이빗 클라우드
(IDC 센터)통합 모니터링 구축
도입 배경
SaaS 서비스를 제공하는 자체 IDC 환경에서 클라우드 시스템에 대한 효율적인 통합 모니터링 필요성
도입 효과
• 베어메탈 컨테이너 전용 HCI(Hyper Converged Infrastructure) 플랫폼 환경 연동 모니터링 구축
• MSA 애플리케이션에 대한 실시간 상세 Trace 추적 모니터링으로 성능 개선 효과
• 개발 및 운영 서비스 별 클러스터 통합 및 개별 모니터링 제공으로 DevOps 지원
• 3D 기반 통합 뷰 제공으로 IDC 센터의 통합 운영 및 관리 효율성 제공