EBIGs는 빅데이터 시스템에 대한 구성 및 보안, 운영 등의 이슈를 해결하고자 개발된 솔루션으로, Apache Hadoop Ecosystem의 모니터링 및 운영 업무에 일관되고 안전한 플랫폼을 제공하여 시스템 관리의 부담을 최소화합니다.
솔루션 소개 자료
호환성 검증을 통한 시스템 구성
국내 기술의 운영 관리 솔루션
확실한 비용 절감 효과
안정적인 기술 지원 제공
특장점
EBIGs는 자체 호환성 검증을 통해 구성된 오픈 소스 기반의 Apache Hadoop Ecosystem과 이를 모니터링하고 운영하기 위한 빅데이터 관리 플랫폼으로 구성됩니다.
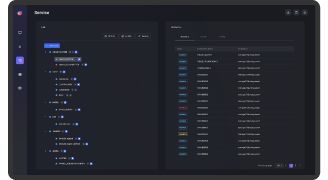
빅데이터 시스템 구성 관리
Hadoop 클러스터 호스트
및 서비스 관리
빅데이터 시스템 설정 관리
서비스별 설정 및 이력 관리
데이터 수집 및 오류 탐지
워크플로우 오류 탐지
및 이력 확인
Hadoop 보안 설정
권한 설정을 통한
보안 정책 운영
실시간 모니터링
Hadoop 서비스 및
리소스 실시간 모니터링 제공
대량 파일 / 디렉토리 브라우징
수많은 디렉터와 파일을
동시에 관리
Hive 워크스페이스
Hive 데이터베이스, 테이블,
단계별 쿼리 관리 및 시각화
서비스 가동 관리 / 경보
서비스 중지 / 가동 관리,
임계치 설정, 서비스 상태 알림
모니터링 뷰
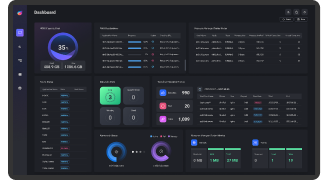
Dashboard
Hadoop Cluster의 통합 감시를 위한 전용 화면입니다. EBIGs는 Apache Hadoop Ecosystem을 시각화하여 서버, 서비스, 노드 상태에 대한 모니터링이 가능하며, Hadoop Cluster의 핵심 지표를 직관적으로 파악할 수 있습니다. 또한, Hadoop Cluster Node를 3D로 시각화한 Dashboard를 제공합니다.
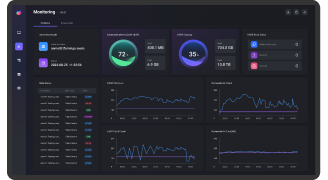
HDFS 핵심 지표 모니터링을 위한 전용 화면입니다. EBIGs는 Hadoop Cluster의 성능 및 상태를 시각화하여, 분산 파일 시스템을 관리하는 Namenode의 가장 중요한 성능 지표인 JVM Heap, GC, Active Namenode, HDFS Capacity, Block Status를 쉽게 파악할 수 있습니다. 또한 HDFS Browser Audit를 통하여 작업한 이력을 추적하고 다운로드가 가능합니다.
Yarn Monitoring
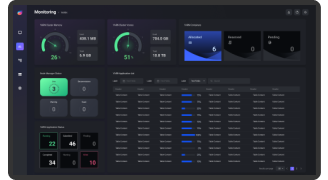
Yarn에 대한 Summary, Log 등의 핵심 정보를 파악하기 위한 전용 화면입니다. EBIGs는 Hadoop Cluster의 성능 및 상태를 시각화하고, Yarn Cluster의 사용량 확인 및 실행 이력 표시가 가능해 애플리케이션을 손쉽게 모니터링할 수 있습니다.
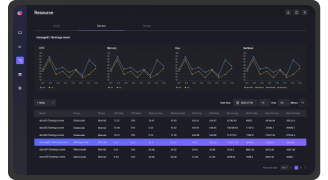
Resource Monitoring
EBIGs는 Hadoop Cluster를 구성하는 노드의 각종 자원 사용량을 실시간으로 모니터링함으로써 자원의 가용성을 극대화할 수 있도록 지원합니다. Hadoop Cluster의 모든 지표들은 실시간으로 수집되어 현재 자원의 상황을 손쉽게 확인할 수 있습니다.
Service List
EBIGs는 Apache Hadoop Ecosystem의 관리 기능을 제공합니다. Web UI를 통해 각 서비스의 설정 값을 수정 및 배포하고 실행 이력을 제공하여 최적의 시스템을 구성할 수 있도록 지원합니다. 따라서 수많은 서비스가 설치되는 Hadoop Ecosystem을 손쉽게 운용할 수 있습니다.
분석 뷰
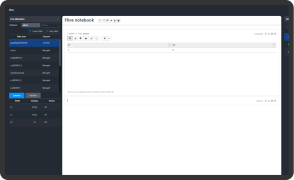
Hive Editor
데이터 관리를 위한 Hive Metastore를 제공합니다.
Zeppelin을 활용하여 Hadoop의 데이터를 RDBMS처럼 쉽게 활용할 수 있습니다. 테이블과 데이터베이스의 관리 및 분석이 가능하며, 조회 데이터의 시각화를 통해 편리하게 분석할 수 있습니다.
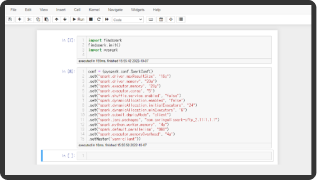
In-memory Analysis
분석 작업 속도 개선을 위하여 Spark-notebook을 제공합니다.
Spark-notebook을 활용하여 다양한 경로를 통해 데이터를 입력받을 수 있으며, 클러스터 환경에서 분산 처리하여 보다 빠르고 정확한 분석이 가능합니다. 또한 Python과 연계하여 머신 러닝, 그래프 알고리즘 기능을 지원합니다.
아키텍처
도입사례
공공
빅데이터 통합 플랫폼
도입 배경
경제 활성화와 효율적 데이터 관리 및 활용을 위한 빅데이터 통합 플랫폼 구축
도입 효과
• Apache Hadoop 기반 빅데이터 플랫폼 인프라 구축
• 지역 관련 데이터 현황을 통합 제공하는 데이터 허브 구축에 성공
• EBIGs를 통해 저장된 빅데이터를 활용하여 웹, 시각화 등의 서비스 제공
전기
전력 재해 복구 시스템
도입 배경
핵심 업무 시스템에 대한 업무 연속성 확보와 상호 백업 체계 구성을 위한 미래지향적 재해복구시스템(DRS) 구축